- Open Data
- SaaS
- JavaScript
- Express
- jQuery
- Backbone
- RequireJS
- MongoDB
- ElasticSearch
- CSS
Open Data in Worldline
My first major job as software architect in Wordline’s R&D team was to build an asset for Open Data projects. These days, we had numerous client projects that include an Open Data component, and this was too exotic for classical IT developers.
We choosed to build a service for collecting, processing, storing and distributing the widest range possible of data. This service should be multi-tenant, always available, and accessible through simple Http(s) APIs. It has been named SmartData
Story of a technological pivot
Worldline teams have a strong Java experience. Therefore SmartData was first written with the state-of-the-art technologies.
- The ingestion and processing toolchain built with Camel EIP and ServiceMix OSGI, to allow data processing customization with simple configuration.
- Data were stored in a CouchDB cluster
- Stored data were accessible through a scalable layer of Jersey Web Services orchestrated with ServiceMix
- The overall system was driven and monitored by a classical Tomcat + Spring + Hibernate + MySQL REST service
- A JQuery + RequireJS back-office GUI was built on top of the the REST web service.
After 6 months, SmartData was working, but was too slow, too complicated, made of too many technologies.
Development has been so hard, and the team so improductive and depressed that our leader decided to throw everything away. One of our colleague, Florian Traverse, gave the idea of using an emerging server technology, Node.js. As an R&D team, we quickly studied the tool, and decided to give a try.
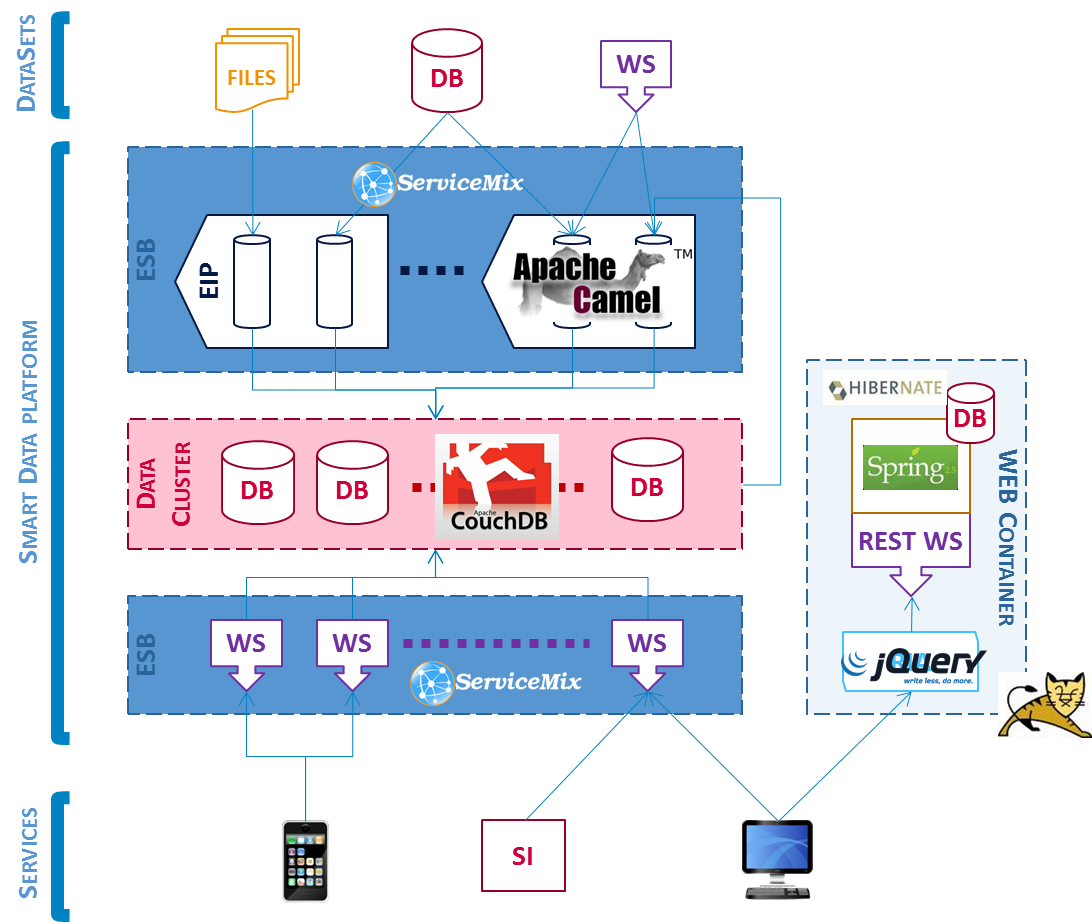
Software architecture of Java based version
(Giant) Leap of faith
The whole project was rewritten in 4 months, by a team of 6 beginners (but half already productive in JavaScript). We reached our goals:
- integration chain and consultation services are really scalable layers
- required performances (integration: 3000 Json documents/sec/server, consultation: 275 searches/sec/server)
- keeping the project flexible enough (functionalities have often changed)
- an automated tested and humanly understandable code base
And the team was really enjoying the work !
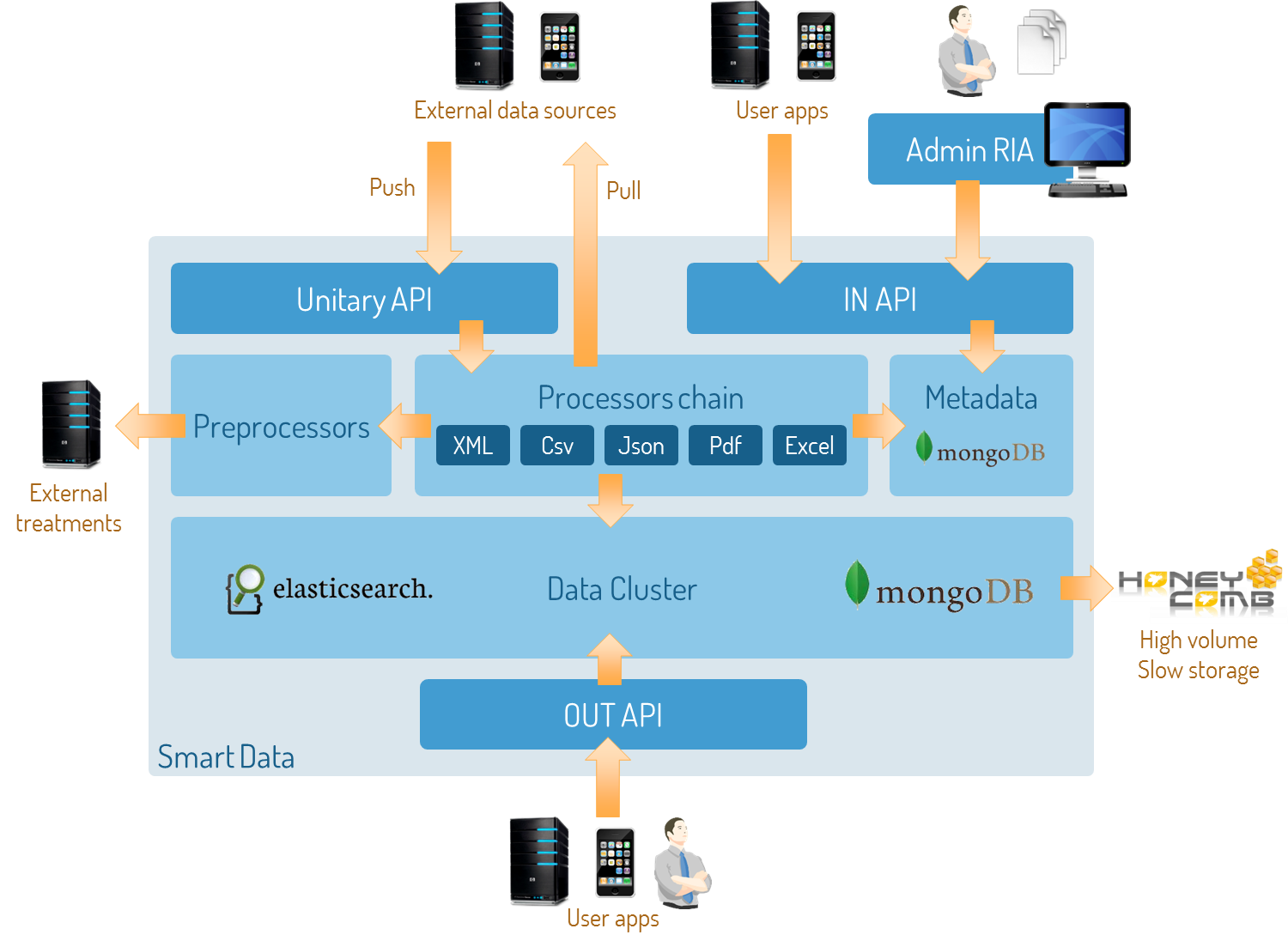
Software architecture of Node.js based version
Under the wood
Inside SmartData, API are powered by Express stateless REST servers, including streaming ingestion API.
The processors chain is a clusterable and configurable chain of simple data processors, ranging from format extractor to data cold/hot storage. When possible (for JSON, CSV, XML…) data is processed as it flows with streams (XlsX impose to load file in memory). Specific data processing can be made internally (by providing JavaScript code from the admin UI) or externally (by calling external REST web service).
Cold storage is provided by HoneyComb (now named RedCurrent, a grid storage like Amazon’s S3) and unitary data is stored as JSON document in ElasticSearch.
Data can be exported as bulk from HoneyComb and also through a REST API, which provides a DSL above ElasticSearch own query language. SmartData allows to merge and mix different data sources into a “stream”, term used to describe a consultable data sink.
All metadata (data source, streams, user rights, processors configurations…) are stored into MongoDB.
API are technically described with Swagger descriptor, thanks to Swagger Jack express middleware. A numerous libraries were used, but we may mention Async, Node-Elastical, Mongoose, Underscore, Request, Readable-Stream, Mocha, Chai and PEG. At this early stage of Node.js (wwe started in version 0.4), we wrote our own logger, configuration manager (with hot reloading) and even an execution sandbox for processors.
Admin UI was first written with Backbone and RequireJS, and was rewrote in 2014 with Angular.
The whole project is composed by 34 node.js packages (processors are individual packages), for a sum of 7500+ sloc. We use Istanbul for coverage and Plato for quality analysis:
-------------------- Gobal coverage
74.82% lines covered (5329)
82.35% functions covered (765)
60.97% branches covered (2770)
74.65% statements covered (5365)
-------------------- Gobal quality
101 jsHint error(s)
7527 single lines of code
15.34 average complexity
66.34 average maintainability
Presentation given on June ‘12 during Techforum (Worldline internal technical conference). Use arrows or space to browse.
The Open Data trend since have lost its glimmer, and SmartData wasn’t involved as desired in client projects. But Worldline is still using it as backend for numerous internal applications, including strategic ones.