

var emitter = new EventEmitter();
emitter.process = function() {
this.emit('change', 'a meaningful data');
}
var listener = {
onChange: function(data) {
console.log('change occured', data);
}
};
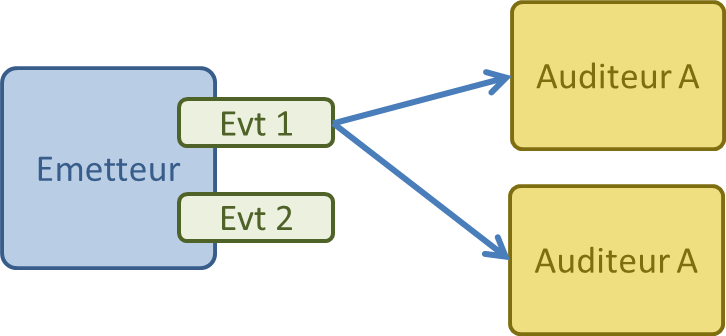
emitter.on('change', listener.onChange);
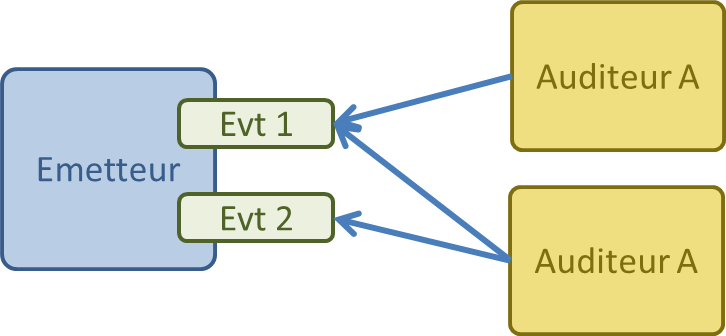
emitter.process();Le design pattern "Publish-subscribe" est très similaire, à ceci près qu'il n'y a pas de bus d'evènement entre les émétteurs et les auditeurs.
Les auditeurs seront notifiés uniquement lorsque l'évènement sera survenu, et s'il n'y a pas d'autres instructions en cours (mono-thread non interrompable)
Généralement, les auditeurs sont invoqués dans l'ordre d'inscription, mais il est périlleux de présumer de cet ordre
Une fonction asynchrone est un cas spécifique d'émission d'évènement : il n'y a qu'un type d'évènement (la fin de l'opération), et qu'un seul auditeur possible (le code appelant)
La page Web est un cas ou chaque noeud DOM est un émetteur, avec différents évènements (click, mousemove...) et 0 ou N auditeurs (des fonctions JS). En NodeJS, il n'y a pas d'équivalent des phases de bubble (remonté de l'enfant vers son parent) et de capture (descente du parent vers les enfants) en moins.
Les appels aux listeners ne sont pas protégés, attention donc aux exceptions synchrones, elles empêcheraient les appels aux listeners suivants !
on(evt, cb) enregistre la fonction auditrice pour evtemit(evt, arg1, arg2...) déclenche tous les auditeurs de evt en leur passant tous les paramètresremoveListener(evt, cb) désinscrit un auditeurremoveAllListener(evt) les désinscrit tousonce(evt, cb) inscrit un auditeur qui sera automatiquement désinscrit après le 1er évènementaddListener() est un alias de on().
La fonction inscrite pour un évènement peut appartenir à un objet (une méthode) ou pas (une simple fonction).
L'émetteur peut invoquer sa fonction emit(), au même titre qu'un autre bout de code externe.
Une instance d'EventEmitter émet elle même des évènement lorsqu'on ajoute un auditeur (newListener) et lorsqu'on en retire un (removeListener).
setMaxListeners(n)error est émit et non écouté, il se transforme en exceptionL'absence de désinscription d'un auditeur est une source de fuite mémoire, car cette référence sur l'auditeur l'empêche d'être garbage-collecté, lui ou ses éventuelles closures
Le warning sur le nombre d'auditeurs est purement indicatif, et n'empèche pas d'en enregistrer plus.
setMaxListener(0) désactive complètement le warning, mais c'est peu recommandé
EventEmitter ayant une méthode start(n).setTimeout).Il est plus simple de créer une fonction tick à part qui s'invoque récursivement
La création d'une classe spécifique est de loin une solution plus élégante.



Les streams en NodeJS sont l'équivalent du pipe Unix
Les buffers stockent les données sous format binaire et sont capable de les convertir dans un encodage spécifique (méthode toString(encoding))
L'encoding 'binary' est déprécié
Les buffers sont des tableaux pré-alloués non dynamiques qui pointent vers une zone mémoire
L'implémentation de nouveaux streams est assez rare, il existe de nombreux formats déjà supportés (1344 package taggés avec le mot clé stream sur NPM)
Un guide pratique pour utiliser et implémenter les streams
Un tutoriel interactif pour expérimenter les streams (14 challenges)
L'annonce du changement de l'implémentation des streams en version 0.10, explication supplémentaire pour streams3
read()
Dès qu'on enregistre un auditeur sur data le flowing mode est enclenché, pour des raison de rétro-compatibilité.
En non-flowing mode, il faut appeller read() jusqu'à ce qu'il renvoit null, chaque appel renvoie un bout de donnée.
L'évènement error ne signifie pas nécessairement que la lecture est stoppée, mais s'il n'est pas écouté, une exception sera levée et les streams dépipés.
L'évènement end vient signaler que la source est fermée ou coupée
Quelques flux Readable : réponse HTTP (ClientRequest), requête HTTP (Server), fichiers en lecture, socket tcp, stdout/stderr des processus enfants, stdin du processus courant
write() pour écrire dans le flux, end() lorsque vous avez terminéwrite() renvoie false attendez l'évènement drain avant d'écrire à nouveau
write() prend en paramètre un callback, invoqué lorsque les données ont été flushé dans la destination, et renvoie un booléen pour indiquer si le buffer d'émission est déjà plein
Une fois que vous avez appelez end(), vous ne pouvez plus écrire
Quelques flux Readable : requête HTTP (ClientRequest), réponse HTTP (Server), fichiers en écriture, socket tcp, stdin des processus enfant, stdout/stderr du processus courant
pipe(writable) qui écrit les données lisible au fil de l'eau dans la destination, et la ferme lorsqu'il n'y a plus de donnéesfs.createReadStream('file.txt').
pipe(zlib.createGzip()).
pipe(fs.createWriteStream('file.txt.gz'));pipe() gère les évènement readable de la source, et invoque la méthode write() de la destinationpipe() ne surcharge pas la destination si la source est plus véloce (non-flowing mode).
Elle renvoit le stream de destination pour permettre le chaînage.
Pour une fois, la syntaxe la plus simple est également la plus efficace ! Usez et abusez de pipe lorsque vous manipulez des fichiers, des sockets, des connexions HTTP...
read()Attention, dans l'ordre des arguments du programme, node est le premier, le nom du fichier est le second, vos paramètres sont donc à partir du 3ème
Les fonctions de création de stream à partir de fichier sont fs.createReadStream() et fs.createWriteStream()
Pour analyze, il est nécessaire d'écouter readable, et d'invoker read()
Sans arguments, read() lit autant d'octets qu'il le peut, mais il est possible de spécifier une taille, et de lire jusqu'à ce qu'il renvoi null
Dans le cas d'encoder, on pourrait aussi créer un stream de type Transform


connect est appelé pour chaque client qui se connecterequest est appelé pour chaque requête entrante. Le callback construit la réponse HTTPlisten(port, hostname, cb) démarre le serveur sur un portclose() stoppe le serveurPour créer un serveur, il suffit d'instancier la classe Server, ou d'utiliser la fonction http.createServer()
Il est possible d'ouvrir un serveur en écoute sur socket unix
D'autres évènements existent pour la gestion des protocoles (upgrade, checkContinue), ou la terminaison du server (close)
En cas d'échec du démarrage du serveur (port déjà utilisé), le serveur émet l'évènement error
var http = require('http');
var server = http.createServer();
server.on('request', function(req, resp) {
resp.setHeader('Content-Type', 'text/plain');
resp.statusCode = 200;
resp.write('Hello world !', 'utf8');
resp.end();
});
server.listen(8080, function() {
console.log('serveur starged on 8080');
});createServer() accepte un paramètre qui est un auditeur enregistré sur l'évènement request
end() accepte un paramètre data et encoding (par défaut utf8), qui revient à faire un write(data, encoding). Le status par défaut étant 200, on peut ainsi simplifier à l'extrême : var http = require('http');
var port = 8080;
http.createServer(function(req, resp) {
res.end('Hello world !');
}).listen(port, function() {
console.log('server started on port', port);
}).on('error', function(err) {
console.error('failed to start server:', err);
});IncomingMessage permet de lire (lecture seule) les paramètres d'entrée (méthode, corps, en-tête...)
ServerResponse permet d'écrire la réponse (corps, en-tête, redirection...)
http.request({
host:'fr.wikipedia.org',
method: 'GET',
path: '/w/index.html?search=Node.js'
}, function(resp) {
console.log(resp.statusCode);
res.on('data', function(chunk) {
console.log(chunk);
});
}).end();http.request()L'objet renvoyé est donc bien une instance de ClientRequest
La requête n'est effectivement envoyée que lorsqu'un appelle la fonction end()
Pour les GET, une méthode http.get(options, callback) évite l'usage du end()
La gestion d'erreur est forcément asynchrone : il faut écouter l'évènement error de l'objet ClientRequest
C'est un client très basique: pas de gestion du proxy, des redirections... On utilisera plutôt le package request à la place
url.parse(str), format(obj) et resolve(from, to)createServer(options)request(options)parse() renvoi un objet détaillant l'hôte, le port, le protocole, le chemin, les paramètres de requêtes, l'authentification...
format() prend un objet respectant le format de parse() et le transforme en chaîne de caractères
La classe https.Server n'hérite pas de http.Server, mais propose la même interface
Elles héritent toutes les deux de net.Server
La classe Socket est utilisée par tous les Servers et ClientRequest pour réaliser les opérations réseaux
Les classes du module net sont utilisées pour tout serveur ou client de protocole autre que http
Pour le wget, on transformera les donnée avec l'encodage utf8, sans savoir pour autant si c'est le bon. Dans l'idéal, il faut utiliser les entêtes de réponse.
Il faut également se connecter directement au serveur, sans passer par un proxy :).

spawn(), exec(), execFile() et fork() pour créer des processusLe modèle mono-threadé peut sembler contraignant et inefficace (un seul CPU utilisé), mais offre une simplicité inédite au développeur.
L'utilisation d'autres processus permet d'exploiter les autres CPUs de la machine hôte, notamment pour des traitement long et/ou intensifs.
Il s'agit bien de processus au sens Unix : code, mémoire, CPU (pile d'exécution) dédiés, sans mémoire partagée entre eux.
Si les fils sont détachés, ils ne s'arrêteront pas lorsque le père se terminera. En revanche, impossible de se "réaffilier" à un processus détaché.
exec() éxécute la commande et renvoi le résultatexec('ls -la', function (error, stdout, stderr) {
console.log(''+ stdout);
console.log('end');
});spawn() éxécute et renvoi le process filsvar child = spawn('ls', ['-la']);
child.stdout.pipe(process.stdout);
child.on('exit', function() {
console.log('end');
});fork() est un spawn() d'un fichier NodeJS, et établi un canal de communication WebWorkersAttention ! l'exécution de ces exemples ne fonctionne pas complètement dans la console NodeJS ! C'est lié au mode REPL (Read Evaluate Print Loop) qui temporise entre chaque commande, et transforme un code synchrone en une succession de commandes temporisées
Dans le cas de exec() et execFile(), nous n'avons pas accès au processus fils : il faut attendre la fin de son exécution pour avoir un résultat
Dans le cas de spawn(), on a immédiatement accès au processus fils (synchronisme), et on reçoit le résultat au fur et à mesure
Quelle que soit la commande utilisée, on peut toujours customiser l'environnement (variables) et le répertoire d'exécution
Comme nous allons le voir, fork() n'est qu'un spawn() particulier pour lancer une instance de NodeJS (V8) sur une fichier donné, et avec un canal de communication spécifique
Un processus NodeJS créé avec fork() est une instance V8 qui a besoin au minimum de 30ms et 10Mb de RAM pour démarrer (dépend du code au démarrage)
exec() est déconseillé : il est susceptible d'être une source d'injection, en plus d'être monolithique, lui préférer execFile()
stdin (Writable depuis le père), stdout et stderr (Readable depuis le père)kill(signal)fork(), son père peut lui envoyer du JSON avec send(data) qu'il recevra en écoutant l'évènement 'message' de process (appels synchrones). WebWorkers'error' si l'on ne peut créer le process (ENOENT : Error NO ENtry lorsque la commande n'existe pas par exemple), s'il ne peut être tué ou si un message ne peut lui être délivré
'exit' est le signal de terminaison normal du fils, avec son code de fin et le signal qui lui a donné éventuellement fin
'close' est le signal de terminaison des flux standards du fils, distinct de 'exit' car il peut être partagé
kill() n'a pas pour effet de terminer le processus fils : utilisé sans arguments, il envoi 'SIGTERM' qui le terminera
Lorsqu'on crée un processus fils avec spawn(), on peut paramétrer ses IO. C'est ce que fait fork()
Si la commande exécutée par le processus fils est un programme NodeJS, celui-ci peut recevoir les messages du père avec process.on('message') et lui renvoyer des résultats avec process.send(...)
Attention ! les messages échangés entre père et fils sont sérialisés de manière synchrone : donc pas de structures cycliques (échec), ni trop volumineuse (ralentissement)
send() peut prendre en 2è argument un handle : on peut transférer une instance de Server ou Socket entre processus. C'est le fondement du module cluster
Il est possible que le parent et ses fils partagent leurs flux d'IO, de spécifier un file descriptor quelconque (fichier, socket, pipe...), ou même de ne pas avoir du tout de flux standards
node edit edit.js. Affichez le code de retour de edit lorsque l'édition se termine, et gérez les éventuelles erreurscandidate = 2
primes = [candidate]
while candidate < n
candidate += 1
divisible = no
for prime in primes
divisible = candidate % prime == 0
if divisible
break
if not divisible
primes ++ primeLe lancement de notepad est très simple sous windows, il prend en paramètre le chemin du fichier édité. Sous Unix vous pouvez utiliser vim
Pour primes, il est nécessaire d'utiliser fork et les fonctions de communication entre processus
L'idée est bien de monopoliser un CPU pendant que l'autre continue d'être disponible
N'hésitez pas à utiliser le gestionnaire de tâches de votre OS pour visualiser les deux processus
process.stdout.write('.');
À la base un module externe, incorporé depuis la version 0.8 (0.6?) au language
Dédié à la réalisation de serveurs Web qui exploitent toute la puissance disponible
Les workers ont le même code, mais peuvent être paramétrés différemment
le module cluster exporte un objet singleton qui est un EventEmitter : 'online', 'listening', 'disconnect', 'exit' permettent de monitorer le cycle de vie des workers
A partir de NodeJS 0.12 le load balancing est géré par l'OS ou par le master.
var cluster = require('cluster');
var http = require('http');
var numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
// code du master : cré autant de workers que de CPUs
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
} else {
// code d'un worker : crée un serveur et traite les requêtes
http.createServer(function(req, res) {
res.end("hello world\n");
}).listen(8000);
}cluster.fork() appelle child_process.fork() sur le fichier courant, il est possible de changer ce comportement avec cluster.setupMaster()
A l'intérieur d'un worker (cluster.isWorker), toute création d'un serveur Http (server.listen()) délègue en réalité la création dudit serveur par le master. Si le serveur à déjà été créé, il est alors partagé
C'est l'OS (jusqu'en NodeJS 0.10) qui gère la logique d'équilibrage entre différents processus qui écoutent sur le même port
Au sein du cluster, le master peut "tuer" les workers, où il peuvent se "suicider"
Comme avec child_process les workers peuvent communiquer avec le master grâce à process.send(), car les workers sont des instances de ChildProcess
Les workers possèdent en plus des propriétés liée au fonctionnement du cluster
Pour communiquer des volumes importants entre processus, ou de manière asynchrone, il est nécessaire d'utiliser un système tiers (messaging queue, base de donnée, fichier...) ou de passer par des spawns qui vont communiquer par leur streams d'E/S standards
Pour constituer un réseau de processus sur machine distinctes, il est aussi nécessaire d'utiliser un système tiers (ou un package dédié)
Les architectures où des processus sur des machines distinctes communiquent sont... des micro-services, ou de la SOA :)
Le retour de cluster.fork() est une instance de Worker sur laquelle on peut brancher l'auditeur 'message'
Par défaut pas de console.log() dans les workers, mais seulement dans le master. Utilisez worker.id pour savoir quel fils a géré la requête
Le code des workers est quasiement le même que dans l'exercice sur le serveur Http
On observe que c'est toujours le même worker qui traite les requêtes : c'est dû à l'OS qui ne considère pas le worker comme chargé. Il faudrait simuler un véritable charge pour observer la balance automatique
